

Recently some things happened that triggered me to reflect on the achievements in the data space over the last 5-10 years.
Firstly, I watched a Coalesce talk with the bold title “Has the modern data stack failed the business?”, which covers at some point how BI tools seemingly stagnated:
Let’s take Microsoft Power BI as an example, because it’s the most popular.
This is Power BI in July 2015 when it was announced as “Generally Available”:
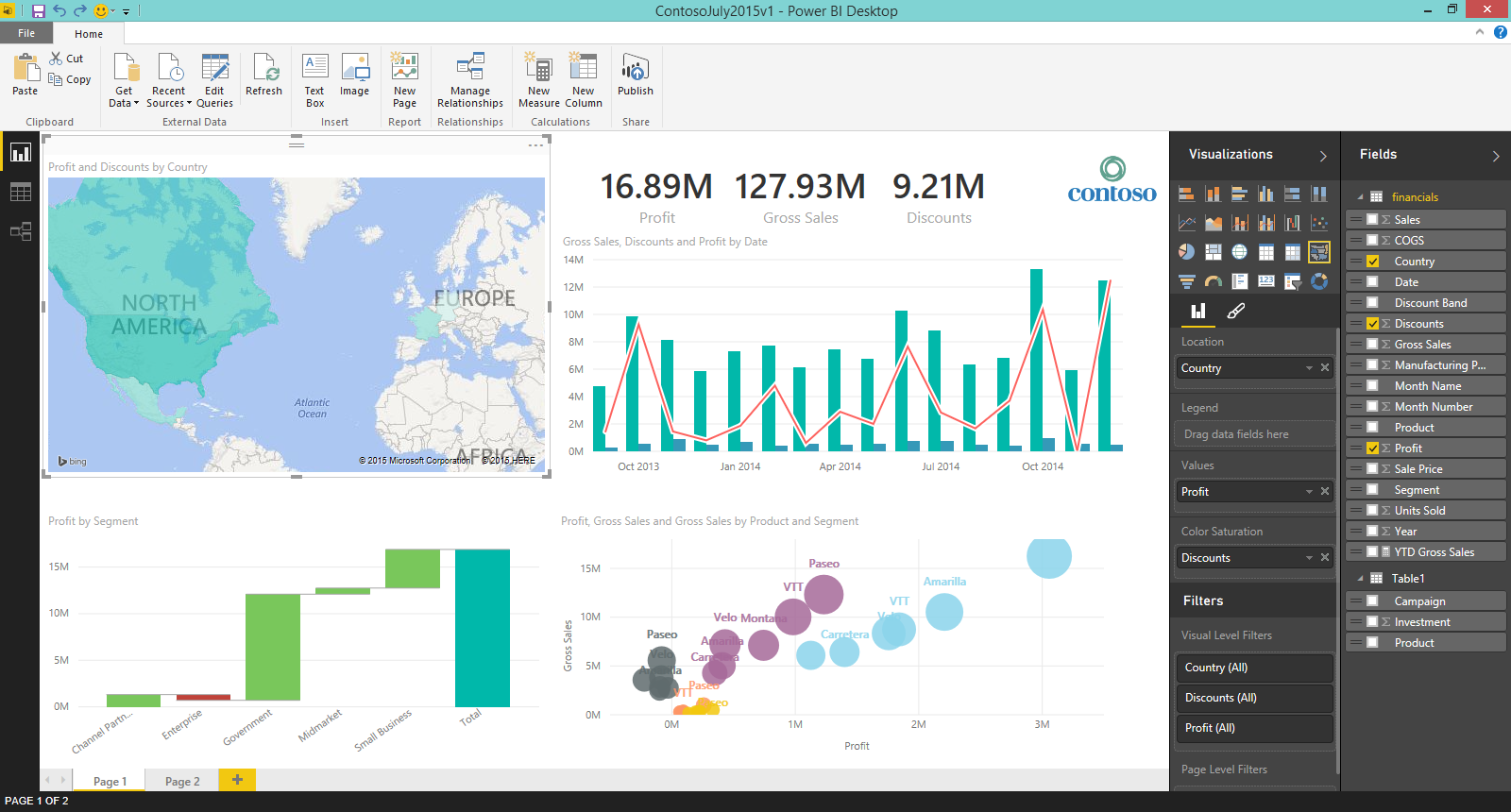
I agree…the navigation bar at the top is a bit more crowded with features nowadays, but wouldn’t you agree that the general experience of building a Power BI report today is very similar to almost 10 years ago?

And this example is just about building the dashboards, not even consuming them. So where was all the development?
The breakthroughs
We ditched on-prem servers and moved computing into the Cloud
We ditched OLAP Cubes and report straight from Data Warehouses instead*
We ditched SQL stored procedures or SSIS and use dbt instead
We ditched custom import-scripts and use Fivetran, Airbyte or dlt instead
*depends on the BI tool
Don’t get me wrong, these developments were good and necessary.
Many data stacks were improvised and testing in production was the norm, not the exception. Who wants to calculate or guesstimate how much memory and storage you need for your server? Being able to focus on the meaningful things is great.
We now have AI-assisted IDE’s in which we write our version-controlled transformation statements, run them through a CI-pipeline before we merge into production, and don’t need to test reports on production tables anymore.
Isn’t that great?
Also, dbt Labs just announced that they acquired SDF which suggests more progress. We might have quicker project compilation, 1000x quicker linting, dialect-agnostic SQL code, and classified fields to add semantic meaning to the mix. Additionally, a growing part of the community claims that SQLMesh is technically superior to dbt. They just acquired Quary to improve their offering further. And everything is written in Rust!
The (lack of) results
We can build the same dashboards as 10 years ago much quicker and more reliably than ever, but users still want to download them as CSV’s to finish the “last mile” themselves.
So you can say: We started to take the wrong turn at some point.
The majority of advancements happened in the “backend”.

Maybe we bought a bit too much into our own hype?
Nearly every company needs some kind of tech/software department to ship their products and generate revenue. Making software engineers twice as productive means - assuming they work on the right things - you can ship your new revenue-generating features twice as fast. The ugly truth is that this way of thinking does not apply to analytics. Working on the “right things” is much more difficult in data. Unless we deliver data to fuel operational workflows (e.g. fraud predictions), analytics and reporting are just a “nice-to-have”, and decision-makers would return to gut feeling & spreadsheets in the worst case.
(Not to mention that hopefully gut feeling & spreadsheets don’t work as well, but my point is: it’s usually not mission critical)
This then means that the sheer focus on developer experience (DX) and more output does not add value by itself. It just accelerates the assembly line of the dashboard factory.
And while the DX improved a lot, you still see dbt-projects with non-DRY logic, bad naming conventions, and a lack of structure.
Part of the reason is, that nowadays it’s common to let business-minded people (Analysts or Analytics Engineers) - like myself - build the tables used to fuel reports and decision-making. They ultimately know better what they need, right? And while that’s true, often nobody teaches them important concepts like coding standards or data modeling. This is by itself not a technology- but a process- or people-problem.
It’s on all of us to use the right tools and the tools right.
However, I believe technology can do its share too.
What I would like to see:
Tools like dbt try to make data transformations mainstream by opening it up to less technical people (soon even without the need to code SQL). I’d like to see innovation also in the data modeling side of things in these tools. By making it easier to design, discuss, and document your data model, data transformations become more organized. Different teams might suddenly start to use the same terms, referring to certain parts of the data model. Right now things are scattered across Miro, Slides, Slack and your Codebase.
Data-modeling as a first-class-citizen
Entity Relationship Diagrams or Star-Schema documentation often are created when models are first introduced and then never updated again.
For a solution that knows all fields, their data types, and their relations to other tables, I’d consider it a long-hanging fruit to have a native ERD Visualizer built into dbt Cloud. There are community-based solutions (like here or here), but you need to know about them to install, and their limitations, and ultimately it doesn’t feel like a native solution, but hacky workarounds.

Wouldn’t it be great to have an always up-to-date representation of your data model, where you could drill up (entity-based conceptual model) or go deep into the physical implementations of columns)? It would allow you to establish a common understanding of business processes, how things fit together in the grand scheme of things, and how their then represented in the platform.

Before building a new table to cover some questions around the sales funnel, it would be a breeze to check out what’s already there and extend that instead of writing myself.
Thinking this one step further, there are two backend-related things I’d like to see to ensure a certain standard of code quality:
Guard Rails for Best Practices
With column-level lineage becoming omnipresent, and thanks to the capabilities of SDF a better understanding of what the columns actually represent through classifiers, I see a lot of potential:
How about proactively preventing somebody from producing the 2nd or 10th version of a mart-table sharing the same grain (primary key) as the others, referencing the same base table(s), and leveraging the same key fields? Even if you just want to tweak the existing “qualified lead”-definition to cover your use case better, do it in the same table as the other.
Yes, we have workarounds such as the project_evaluator-package, and some of these features have also been integrated into the dbt Explorer.
But with a better “understanding” of the project and its metadata, I’d expect also more guardrails to enforce best practices.
AI Code Review
Senior colleagues can’t have their eyes everywhere, but somebody else can: 🤖
dbt Cloud or Paradime have introduced AI Assistants helping you to write and update dbt documentation. That’s great! I never encountered anybody who truly enjoys writing documentation. It’s tedious and can consume a lot of time and is often not considered crucial. It then often gets deprioritized, neglected, and skipped. Reducing the friction of documentation was important.
But let’s think about this further and bigger:
I - a more junior member of the team - create a Merge Request to suggest changes: Wouldn’t it be great to have somebody pointing out
naming inconsistencies based on general or project-specified best practices
hinting at similar existing models to adapt over re-inventing the wheel
general design considerations
I would appreciate that and I think you would, too. Plenty of companies doing their first steps in data might not even have such a person on the payroll at all!
Don’t get me wrong: I don’t want to replace human MR review, but enhance it.
You might think that best practices and more robust data models themselves don’t deliver more business value. And that is true!
However, I don’t think that without these practices and standards - monitored and established by humans or technologies - it’s even harder to deliver value to the business. New metrics will take longer to deliver, fail more often and the trust in data will diminish.
And while these topics are indeed on the “backend side”, I already see a lot of good progress on the “frontend” side of things:
Light at the end of the tunnel?
To address the dashboard factory statement from earlier:
It’s often a result of data teams interpreting their role as too passive and just delivering what unguided business stakeholders request:
A breakdown here, another version of the same report for another business unit there.
You might think: if I could just answer these business questions faster, it would add more value. But it’s a trap: the more questions you answer, the more follow-up questions you’ll receive. The key is to focus on the important questions:
Metric Centricity
Metric Trees are essentially a hierarchical representation of how an overarching goal (e.g. Revenue) is the result of input business events (e.g. New Customer Revenue + Returning Customer Revenue), which have input events on their own (e.g. Orders x Avg. Price). While not new, it picked up in buzz - at least in my bubble - in popularity 2 years ago.
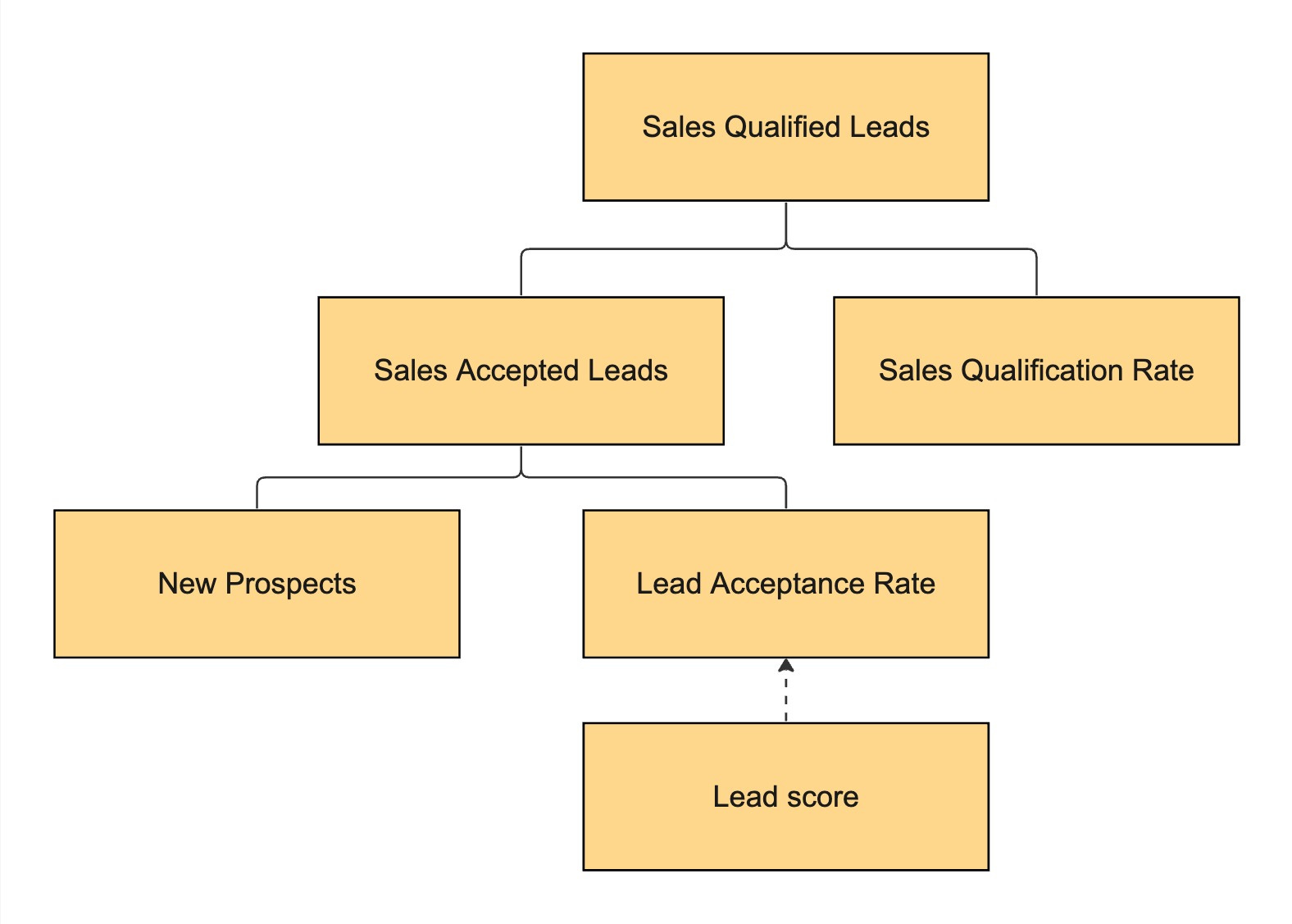
By benchmarking metrics of the tree either against targets or against a previous period, the users are guided towards the defined input metrics when tracing down the hierarchy to find answers to why last month exceeded targets.
This is great in the sense that you’ll need fewer dashboards but then rather ad-hoc deep dives to answer questions and it has its clear focus on the metrics itself.
Too many reporting tools require you to “think” in tables, but ultimately the result boils down to a metric broken down by various dimensions. Organizing data in tables and creating fixed charts is just a necessity. Tools like Steep, Count, or Push.ai think that radically differently. Lightdash - starting with a more traditional BI approach natively integrated on top of dbt - also recently announced their Metrics Spotlight and Canvas feature.
Obviously, in the age of AI, you also have offerings around AI Assistants or Chatbots like the ones of Zenlytic who inspired this post with their Coalesce talk in the first place. Thoughtspot started with a search-based analytics approach and now offers more and more AI features as do the juggernauts of Power BI and Tableau.
I’m, skeptical by nature, not super optimistic if analytics chatbots will be the final answer in the short term. Without guidance - of the Metric Trees or a codified representation of business processes to hunt for answers by itself - I’m afraid that it will only lead to more questions, more answers, and a worse signal-to-noise ratio.
Shift-Left Business Logic
There has always been a trade-off between speed & quality. Centralized data models and long waiting times vs self-service answers but inconsistencies.
Semantic models only partially solve this problem, but they can slow down business domains with their central definitions.
Tools like Euno try to address this by allowing you to identify and observe important business logic inside BI tools and transfer it into your existing debt project. Modern BI Tools like Omni even built solutions for that into their offering.
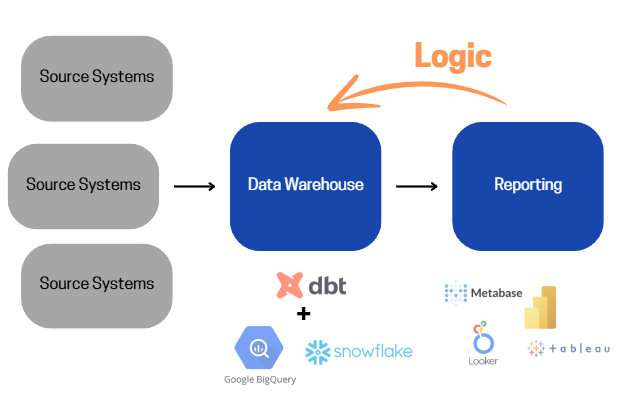
While I doubt that overly (!) complex BI Logic of dashboards can be easily shifted with two clicks into an arbitrary dbt-model without creating a mess there, it’s great to see the awareness of the gaps in these workflows.
Additionally, both companies are also rather young and I’m excited for future progress.
“Aware” BI Tools
Something I haven’t seen, but I’d dream of is that BI tools telling you when something similar has been created before. This has the option to save you lots of time and avoid inconsistencies.
Last week’s sales broken down by product? It’s right here —> …
Did you want to filter for new customers? Just add the filter here ____ or make the metric switchable.
It happens too many times that 10 versions of the basically the same analysis are created. The reasons are mostly that either some minor details are different or that you simply do not know (or don’t have access to) existing assets.
Conclusion
It’s not all bad. “Doing data” is so much easier than 10 or 20 years ago.
I wouldn't want to switch with anybody building OLAP Cubes and Stored Procedures in TSQL. But we need to stop being obsessed with improving our DX even further and focus on delivering value to your stakeholders. All tools required to do that were available 20 years ago and nowadays it’s even simpler.
Extracting and storing the required data has become a commodity
You don’t need to maintain and actively manage your computing resources
Data transformations can be defined faster and more robustly than ever and
BI Tools become metric-centric and allow you to “outsource” business logic
Hopefully, it will be easier than ever to build and maintain a data model. The conceptual part is already hard enough. Proactive guardrails in our transformation pipeline and peer reviews from the cloud would help us to upskill our domain experts who lack the technical foundation for scalable code.
I hope to have triggered some thoughts in you.
What’s your perspective on the recent developments? Which topic maybe deserves a deep dive?