
AI Agent Harness demystified
Deep diving into OpenCode vs. Altimate Code to see what makes agents actually smart

Harness?!
When I first heard 'harness' in the context of AI agents, I assumed it was buzzword dressing for a system prompt. I was wrong — and the gap between those two things turns out to matter a lot.
(If you feel the way I did, I suggest you watch the YouTube video below now or afterwards to clear things up.) Also, LangChain’s blog post intro is great)
But in very simple terms:
Agent = Model + Harness
Harness includes System Prompt, Skills, Tools, Orchestration, Sandboxing etc.
Think of the Large Language Model (LLM) as the engine. The harness is the chassis, the steering, and the sensors—the engineering that connects that power to the wheels. Together, they make the car—the whole AI experience that you actually “drive”. Using the same engine in a generic sedan versus a specialized racing vehicle can lead to radically different track times.
How can we understand that further? Let’s break it down:
Altimate Code is an open-source coding agent that claims to outperform other coding agents (e.g., Claude Code) by leveraging its “data engineering harness”.
OpenCode, being a provider-agnostic alternative to the famous Claude Code, is another open-source coding agent.
Why is that relevant? Altimate Code is a fork of OpenCode and therefore shares the same code foundation.
So I ran both repositories through Cursor, asking some guiding questions to see exactly how they are built and where they differ. Now, I’ve realized the harness is actually the real difference-maker.
We see this clearly in the Altimate AI Benchmarks: While using inferior models (Claude Sonnet), it beats more powerful Claude Opus and other Sonnet implementations. The difference? The tools and context, provided by the harness.
What is a Harness Anyway?
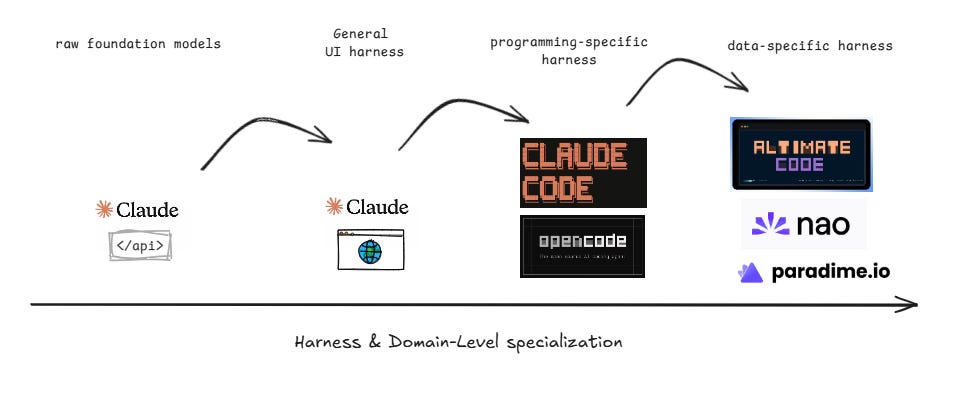
Think about how you can use an LLM in the most “raw” way.
1. Plain API Call (The Bare Engine)
At its most fundamental level, if you use the Anthropic or OpenAI API directly, you are just sending raw text and receiving raw text back.
The model reads exactly what you sent.
It infers the logic from that specific snapshot.
It suggests a plausible change based on its training.
But you have to write your own code to manage history, format the output, and handle file uploads. There is no harness here at all—just raw horsepower.
2. Claude/ChatGPT UI (The Basic Chassis)
When you paste a script into the web UI, the platform provides a basic harness around that raw engine:
It manages your conversation history so the model “remembers” the chat.
It can format the raw text into readable markdown and syntax-highlighted code blocks.
It handles file uploads and parses them into text behind the scenes.
It makes the engine usable for everyday tasks. While it’s great for one-off snippets, it’s still blind to the rest of your code project. It doesn’t know about your database config files, your project-specific logging helpers, or whether that new import it just suggested actually exists in your environment.
3. OpenCode (The Generic Agent Harness)
OpenCode takes the same Claude model but wraps it in a coding harness. This gives the model a library of real tools, implemented as TypeScript handlers in the repository (can be found here, along with their instruction prompt):
bash: Executes shell commands, allowing the model to run your build or test suite.
read & write: Direct filesystem access to inspect and modify code.
edit: Performs structured string replacements to prevent “hallucinated” code deletions.
grep & glob: Powerful search capabilities to navigate large codebases.
task & skill: Orchestrates sub-agents and loads specialized “playbooks” for complex workflows.
In this environment, the model stops being just a chatbot and starts acting like an agent enabled by its tools. It’s no longer just guessing; it’s executing, verifying, and iterating in a loop.
The Myth of the Static Prompt
One common misconception I had is that the system prompt of an agent is just a massive, static text file. A big learning here: In reality, OpenCode assembles the system prompt at runtime.
When a session starts, the harness pulls together several dynamic pieces:
1. Provider Base: It picks a base instruction set optimized for the specific model (e.g., src/session/prompt/anthropic.txt for Claude).
2. Environment Fingerprint: It injects a live `<env>` block containing the current working directory, the workspace root, and even today’s date.
3. Dynamic Skills: It queries the repository for available “skills” and injects their descriptions so the model knows what specialized workflows it can trigger.
This means the “prompt” is highly adaptive to your situation—it’s a living reflection of your actual project state. The context is all about those “little things”: it knows I’m running on WSL2/Linux and not on a Mac like the majority of developers, and it doesn’t get “confused” about “future dates” because the harness injects today’s actual date into the prompt, grounding the model far beyond its static training cutoff.
The Execution Loop: What happens after the LLM speaks?
But a harness is more than fancy context engineering before hitting “Send.”
For coding agents, the harness is equally critical after the LLM inference.
When the LLM generates an output in a web UI, you just read the - often rendered pretty - output. When it generates an output inside a coding harness, it usually generates a tool call (often formatted as JSON or XML). The harness intercepts this output and manages the execution loop:
1. Tool Execution & Feedback: If the LLM outputs a command to run `dbt test`, the harness executes the shell command, captures the raw `stdout`/`stderr` logs, and feeds them back into a new prompt. The LLM then reasons over the error without you having to copy-paste anything.
2. Error Recovery: If the LLM hallucinates a file path or outputs malformed syntax for a tool call, the harness catches the crash and automatically prompts the LLM: “That file doesn’t exist, try again.” You never even see this hiccup.
3. Telemetry & Learning: (Altimate Code excels here) After a successful session where a bug is fixed and tests finally pass, the harness can automatically extract the successful pattern and save it to persistent memory. It learns from the *outcome* of the loop, not just the initial prompt.
So, the harness is not just a prompt assembler—it’s a continuous feedback loop that connects the LLM’s “brain” to the real world.
The Case Study: OpenCode vs. Altimate Code
OpenCode is the generic “Software Engineering” harness, Altimate Code is the “Data Engineering” specialist. Since Altimate Code is an open-source fork of OpenCode, we can see exactly how they differentiated the harness for data-specific tasks. Data tasks have a unique challenge, like being able to “see” the values of the data in order to process it properly. Looking only at the table schema and the transformation code can be quite useless if you want to find out which filters to apply additionally.
The difference becomes obvious when you ask a domain-specific question like: ”What’s broken in this dbt test?”
The Side-by-Side Diagnostic Path
Here is how the two harnesses handle the exact same user query using the same underlying model:
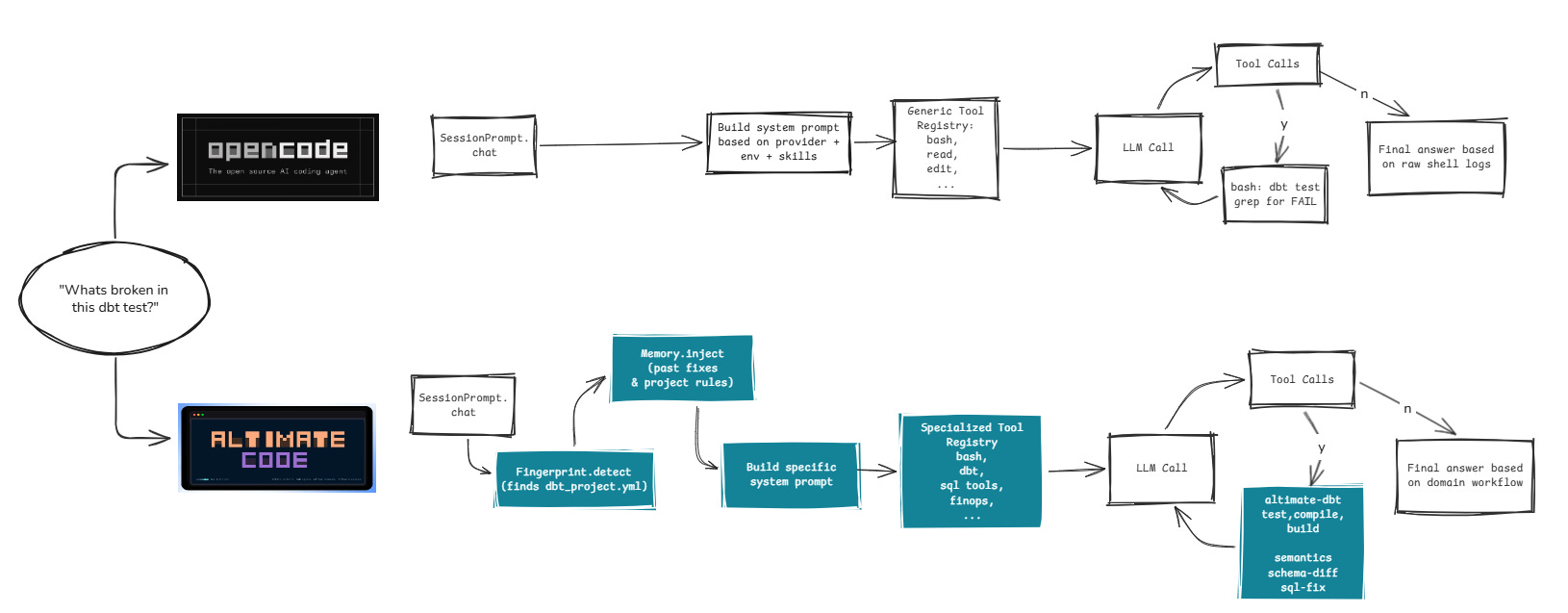
OpenCode does what a programmer would do on its very first day without any onboarding: it scans through the codebase, runs commands and reads the logs. It’s smart, but it’s manual.
Altimate Code understands the domain. It detects the dbt environment, pulls in specialized workflows, reproduces and classifies the failure, and then uses semantics, lineage, or fix tools as needed.
You can compare this set of tools to the one available to OpenCode.
To make this concrete, imagine asking: ”Where does this field originate from?”
In OpenCode:
The agent runs a string search (`grep`) across your entire repository.
If the column name is common (like `status` or `user_id`), it gets bombarded with hundreds of matches.
It then has to manually read SQL files, guess the joins, and try to piece together the lineage like a detective sifting through paper files.
Result: It’s slow, prone to hallucination, and struggles with complex multi-hop joins.
In Altimate Code:
The agent calls a native tool (like `altimate_core_column_lineage`).
This tool doesn’t grep text; it uses a proprietary, compiled Rust engine to parse the actual SQL AST (Abstract Syntax Tree) and walk the dependency graph.
Within milliseconds, it hands the LLM the exact upstream model and source column.
Result: The LLM doesn’t have to guess; it is handed the deterministic ground truth.
Extra Example: Paradime
Paradime just released DinoAI v3.0 benchmark a few days after Altimate Code came out. They tested the same underlying model (Claude Sonnet 4.6), as a baseline versus their specialized DinoAI agent and scored even better than Altimate.
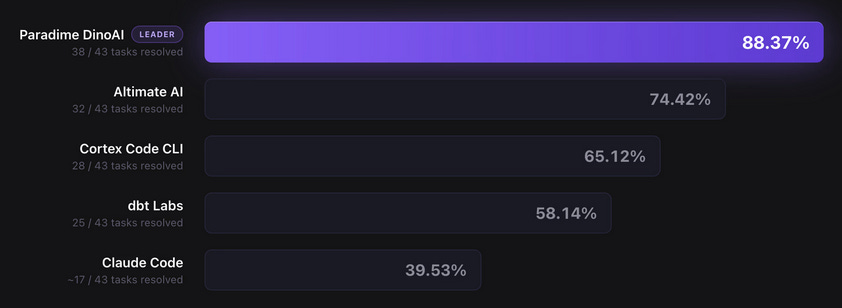
The Caveat:
It's closed source, so we can't verify what their harness actually does — treat this as directional evidence, not proof. Benchmarks can be overfit to specific examples, and your use case may differ. Test it yourself.
But the general message should be clear:
The performance gain isn’t coming from a “smarter” brain (more powerful LLM), but also, most probably, from a more sophisticated harness.
Under the Hood: The Altimate Advantage
So, what are the three main components that actually make a “specialized” harness?
1. Pre-loop Fingerprinting
Before you even get your first token back, the harness scans the environment. If it sees a dbt_project.yml or a profiles.yml (using a fingerprinting tool), it tags the session as dbt. Fingerprinting results could be:
["dbt", "dbt-packages", “data-engineering”, "bigquery", "sql"] or
[”airflow”, “data-engineering”]
This allows the system to filter out irrelevant tools and promote the most useful skills for that specific task.
2. The Deterministic Engine
This is the part where there is the most “magic” of Altimate: Instead of letting the LLM “hallucinate” about SQL joins or column lineage, the harness provides a compiled, proprietary Rust engine - called “altimate-core” - interfaced through native dispatchers.
When the agent needs to know why a test failed, it doesn’t assume:
it calls a deterministic tool to trace the column lineage or check for cartesian products. It uses “ground truth”, reliably in 1,000 out of 1,000 runs.
3. Persistent Memory
We’ve all been there: you fix a bug, and three sessions later, the AI suggests the exact same broken pattern again.
The specialized harness solves this by saving “learned patterns” and “team standards” (NO RIGHT JOINS!!!) as markdown files in your repo (committable to Git!) using memory extraction tools. The next time you start a session, those rules are injected back into the prompt. It actually learns from you.
This is something you can achieve by using team-wide CLAUDE.md-files or project-rules, but it’s still nice to have it baked in natively.
Final Thoughts
The generative AI hype often focuses on who has the “smartest” model. But for those of us doing real work—especially in data—the model is only half the story.
The vast majority of training data (and benchmarks) for AI Coding Agents understandably focuses on classic software engineering.
Examples like AltimateCode, Paradime and nao show that with clever engineering, you can squeeze a lot more juice out of these smart, but general agentic frameworks.
If you’re building on top of an LLM today, the question worth asking isn’t which model — it’s what you’re wrapping it with. There’s a dismissive narrative in the industry that products like Cursor are “just AI wrappers” — as if the wrapper is the trivial part. The evidence points the opposite way: the wrapper is where significant gains are happening. Examples like Altimate Code and Paradime show what's possible through harness engineering alone — without touching the model at all.
Hot take: As compute becomes more scarce, and focus shifts on API token burn, an interesting bet might be small, fine-tuned local models paired with a well-engineered harness — rather than throwing ever-larger frontier models at the problem. We're already seeing the first hints of this: a 1.7B model beating a 744B frontier model on a specialized task.
p.s. I’m not affiliated with any of the mentioned tools. I have barely used AltimateCode, and have yet to get my hands on Paradime. This read should serve just as a tangible case study around clever agent engineering.