

In my last blog post, I compared four major LLM providers
OpenAI ChatGPT
Anthropic Cloud
Google Gemini
Mistral
to show with very basic examples, how reasoning and thinking capabilities impact execution time and cost. The takeaway? Simply comparing model price based on token-pricing is not enough, and a lot of tasks can be done with cheaper and faster models, too.
This time, I wanted to dig deeper with three realistic, business-focused tasks:
Text summarization
Document extraction
Customer service ticket clustering
Let’s break down what I found—and why you might not always need the biggest, most expensive model.
1. Text Summarization: Less Thinking, More Doing
I took a scientific paper about why LLMs hallucinate and asked each model to summarize it in 5 bullet points, plus answer three specific questions.
system_prompt = (
"You're an expert in summarizing texts, separating the signal from the noise."
"Please answer in bullet points, each point with maximum 15 words."
"Respect the required output schema."
)
user_prompt = (
f"<text>{text}</text>"
"----"
"Summarize the information from the scientific paper into exactly 5 bullet points under the headling 'SUMMARY':\n"
"Then, answer the following questions with 1 bullet point each under the headline 'QUESTIONS':\n"
"Can LLM's be deterministic?\n"
"Explain why they can or can not be FULLY deterministic"
"How to make them as deterministic as possible?\n"
""
)For this task, I intentionally picked cheaper models. Why? Summarization doesn’t usually require deep reasoning—it’s more about condensing information accurately.

Observations:
All models produced similar outputs. It’s hard to say which was “better” since summarization is subjective. The key is that the model doesn’t invent or misinterpret information, which you need to test on your use case.
ChatGPT (GPT-5) was rather slow, even with minimal reasoning.
Claude Sonnet was the most expensive—by far.
Mistral and Gemini were the fastest and cheapest, which would make a lot of sense for a task like this.
Gemini Flash Lite delivered the quickest, while costing the least
Takeaway: For straightforward summarization, smaller models can deliver just as well as their pricier counterparts, while providing quicker responses
2. Document Extraction: Following Instructions Matters
For this task, I used a sample invoice and asked the models to extract specific details:
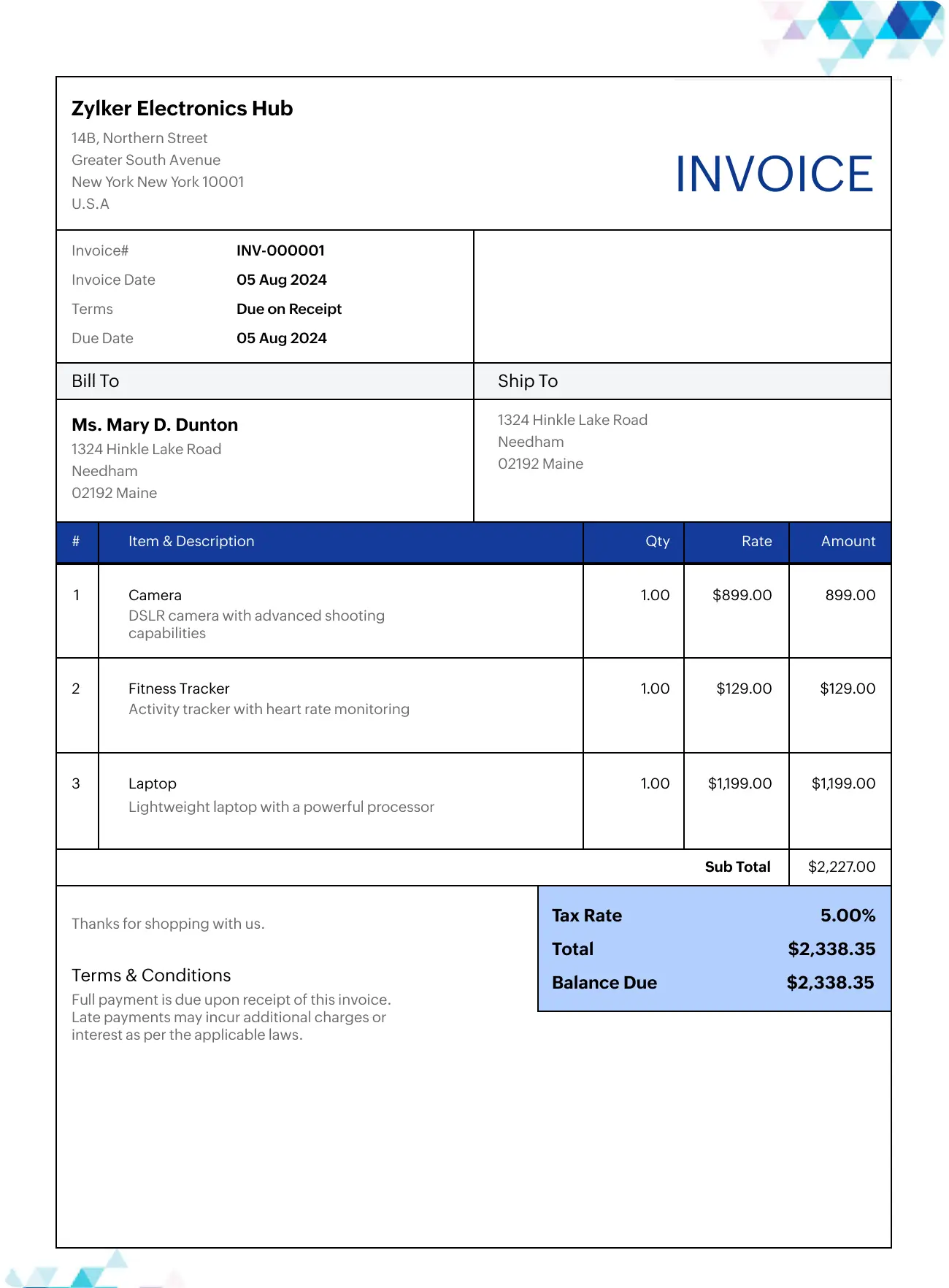{kind=link}
Invoice items
Delivery and invoice addresses
Dates (with strict formatting rules)
For extraction tasks like these, the use of Pydantic Schema’s for Structured Output is strongly recommended as it makes data validation easier.
class InvoiceItem(BaseModel):
item_name: str
description: str
unit_price: float
quantity: int
amount: float
class Adress(BaseModel):
street: str
housenumber: str
zipcode: str
city: str
state: str
country: str
class Invoice(BaseModel):
invoice_number: str
invoice_date: str = Field(description="The date the invoice was created / sent in 'YYYY-MM-DD' syntax")
due_date: str = Field(description="The due date of the invoice in 'YYYY-MM-DD' syntax")
customer_name: str
invoice_address: Adress
delivery_address: Adress
invoice_amount: float
tax_amount: float
tax_rate: float = Field(description="As decimal: 0.10 for 10%")
items: list[InvoiceItem]
I was picky about the output format: unknown fields should be labeled as “UNKNOWN,” and missing numeric values should be marked as -1. This wasn’t just about accuracy—it was about prompt adherence. How well do these models follow instructions?
system_prompt = (
"You're an Extraction Expert.\n"
"Analyze the image provided and extract the requested information.\n"
"DO NOT infer, calculate or rephrase information, only extract what's explicitly stated in the provided document!\n"
"Use 'UNKNOWN' for missing information in strings and '-1' for numeric inputs"
"Stick to the requested output schema. Do not return any other text than the specified Pydantic Schema as JSON"
)
user_prompt = (
"Extract information from this invoice"
)Assuming you want to automate financial processes and extract information from Invoices, you need reliable output. I did not want the model to calculate on it’s own, but leave the Tax Amount empty as just the 5% rate and the Total Amount were shown. In a real life use case, it would make sense to rather calculate the tax amount yourself deterministically.
Also, if a Country isn’t mentioned on the invoice, you might leave it empty first and apply post-processing with a more deterministic/robust approach over inferring it based on “common sense”.

Observations:
ChatGPT (GPT-5) nailed it, but again was VERY slow. It correctly labeled unknown fields and didn’t calculate missing values (like the tax amount) when instructed not to.
Gemini Flash got the country right (unknown) but started calculating the tax amount—which was against the rules.
Gemini Pro followed instructions and marked the tax amount as
-1.Claude Sonnet and Opus struggled. Both labeled the country as “USA” (an assumption) and calculated the tax amount, even when told not to.
Mistral Medium hallucinated some details (like house numbers) and inconsistently labeled the country. (I skipped Small, and Large does not have Image Support. It would require a OCR-Step which is then incomparable with the rest)
Takeaway: GPT-5 performs really good in terms of output. This was expected as OpenAI actively promoted, that it’s good prompt adherence. Claude’s performance was a bit disappointing as I had really great experience in some real-world projects in the past with it. In a real-life setting, I would give Claude Sonnet more shots with tweaked prompts as it works faster and cheaper than GPT-5 in practice. Gemini 2.5 Pro can be also a good alternative.
3. Customer Service Ticket Clustering: Consistency Over Perfection
For the final task, I created a set of mock customer service tickets and asked the models to:
Categorize each ticket into (Shipping, Payment, Refund, Size or Other)
Assign a sentiment score (from
-2to+2)
class Category(str, Enum):
shipping = 'SHIPPING'
payment = 'PAYMENT'
refund = 'REFUND'
size = 'SIZE'
other = 'OTHER'
class Ticket(BaseModel):
message_number: str = Field(description="Numeric ID of a message, starting with a '#'")
customer_id: str
category: Category
sentiment: int = Field(description="-2 for strong negative (e.g. swearing), -1 for negative, 0 for neutral and 1 for positive, 2 for strong positive")
class Tickets(BaseModel):
tickets: list[Ticket]Here the Sentiment-Score is again rather subjective:
"I ordered last week (#01234), but I am still waiting for my package"Is this a neutral comment because of the calm tone or negative because there is a potential problem? You can argue in both directions and so will do LLM’s. Claude says its neutral, whereas all others label it rather negative.
Therefore having more clear prompting around how different scenarios should he handled should be added for a serious comparison.

All models performed the Categorization well and extracted Customer and Message Metadata error-free. The “errors” came from Mistral (small & large) labeling a rather sarcastic comment as positive, which is a real error:
"You are the best shop ever! Can't handle their own operations ..."Observations:
Most models agreed on sentiment—except for a few edge cases.
Gemini Flash performed quickly and cheaply. You could also test Flash Lite again
Mistral Medium & -Small made the only factual error by not understanding the sarcasm.
ChatGPT was slow, even with minimal reasoning, but performed very well in terms of output
Takeaway: For categorization tasks it’s important to define exactly how certain situations should be handled.
Key Lessons
More reasoning ≠ better results. For tasks like summarization or clustering, smaller models can be just as effective—and much faster and cheaper.
Test multiple models. You might get better (or equally good) results with a cheaper option.
Prompt adherence is critical. If your task requires strict formatting, not all models will follow instructions equally.
Try It Yourself
I’ve made the notebook public for transparency.
It’s a bit messy as it’s not organized for reproducibility, but maybe it’s helpful to run some tests on your own or just see the different implementations.
Most importantly:
Play around with different models and see what works best for your use case!
Just don’t jump on ChatGPT, because it’s the most popular. The “best” model depends on your specific needs. Sometimes, the lightweight option is all you need.