

So, you've hired your first data person. Ideally, this individual is a data generalist or an Analytics Engineer, as discussed in my previous post.
But what's next? How do you scale the data function in your company from here? Let's break it down.
Identify Bottlenecks and Prioritize Needs
The first step is to identify the bottlenecks in knowledge, expertise, and strategic importance within your business functions. This demand-based approach will help you understand where to focus your efforts.
Ad Hoc Requests and Stakeholder Management
Since your first hire needs to
integrate a new data source for Marketing
help Product Management with the results of an A/B Test
extend the Dashboard for Sales
… all in parallel, it can become a challenge manage stakeholders and dive deep enough into the topics the help sufficiently. They might be drowning in ad hoc requests, which can be overwhelming. Instead of seeing this as a problem, consider it a sign that a data analyst or business analyst could be a valuable second hire. This addition can strengthen your data team by filling in the gaps where your first hire couldn’t put enough emphasis on, ensuring that stakeholder needs are met efficiently.
Specialized Skills for Specific Needs
Depending on your company's focus, you might need specialized skills. For example, if you're an e-commerce company emphasizing Conversion Rate Optimization (CRO) or user experience (UX), a Technical Web Analyst with a background in CRO could be invaluable. This person can monitor website performance, track product landing pages, and ensure effective event collection.
Or somebody with Marketing Analytics/Science background, IF Marketing is a competitive advantage of your company and you need to strengthen your expertise in things like Performance Measurement and Attribution.
Technical Expertise and Pipeline Management
If your data hire struggles with integrating exotic source systems, which cannot be covered by Fivetran or Airbyte, it might be time to bring in a Data Engineer. This is especially true if your current pipelines are failing frequently and consuming too much time. A data engineer can ensure that your data infrastructure is robust and reliable. Also high compute cost might be a flag that somebody with deeper technical understanding is needed.
Balancing Analytics and Technical Needs
Generally, it makes sense to hire more on the analytics end than on the technical and data science end. This ensures that what is built by your engineering generalist serves the business's needs. Thanks to managed services it’s doable to run a Pipeline and keep the Data Model governed with less people, than doing the analytics work in collaboration with downstream stakeholders.
Business analysts or data analysts can bridge the gap between technical implementation and business requirements.
When you plan to extend your data function beyond the first hire make sure to assess where the interests, strengths of the first hire are and were “external” help is needed in the form of new hires.
Centralized vs. Decentralized Data Teams
In the beginning, a centralized data team of a handful of people can work well. However, as your organization grows into 100 people and above, consider adopting a hub-and-spoke model. This model involves a centralized engineering and platform team (or even a single person maintaining the data warehouse) with analysts dedicated to specific business units like marketing, product, or sales.
The Hub-and-Spoke Model
In this model, analysts ensure that the data warehouse answers the business's questions and that the data needs of each function are met. They also serve as analytical sparring partners for their respective business units. This approach scales well with growing organizations and ensures that context is not lost.
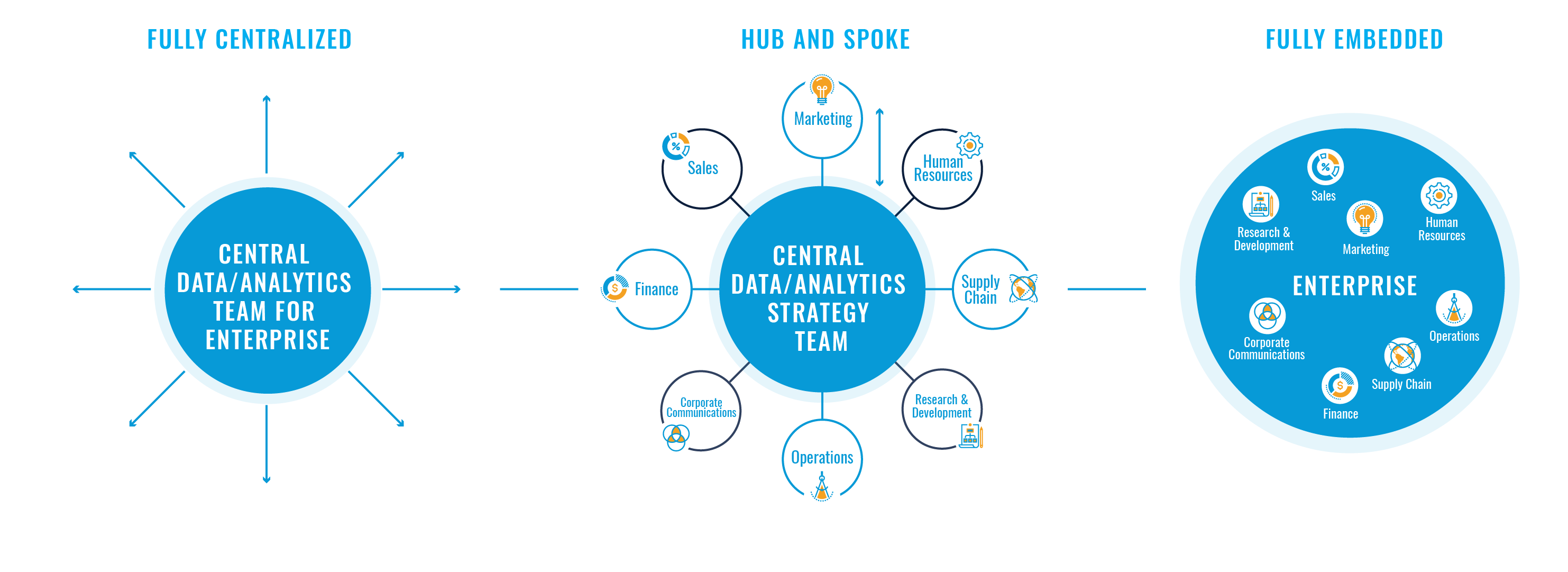
Avoiding the Pitfalls of Full Centralization
Centralization works initially. For companies with 500 or more people, a fully centralized data team is often ineffective and is rather a “centralized bottleneck”. Context is key in analytics, and it can only be captured by working closely with each business unit day by day.
The Overkill of a Data Mesh
Data Mesh, where each business unit has its own data function and builds its own pipelines, is an overkill for smaller/medioum organizations. While it can work well for companies with tens of thousands of employees, it's usually unnecessary for those with fewer than 2,000 people, in my point of view.
Conclusion
To sum things up, start with a generalist and listen to where there is more demand for certain skills or where bottlenecks exist. Hire accordingly to build a complete portfolio of skills within your data function to support the business's needs. Remember, these needs can change over time, so stay flexible and adaptable.