
The Write-Audit-Publish Pattern
How to deliver curated datasets to your stakeholders (with dbt)

EDIT: On 2024-01-14, dbt Labs announced the acquisition of SDF Labs. At this point, it’s unknown which of (and how) SDF’s features will be integrated into the free dbt-core and paid dbt Cloud offerings, but WAP has been natively integrated into SDF so far. It might be, that the suggested solutions in this post won’t be necessary anymore and native support for WAP will be built into dbt soon. But until then, I hope the ideas are still helpful :)
The Issue
Let’s say you've built your first dbt pipeline.
Maybe you've already implemented the 4-Layer architecture, which I discussed in my previous post. And hopefully, you've even added some dbt tests to ensure data quality. That's great! But there's still a potential issue we need to address.
Here's the problem: When you run the standard
dbt run --target prod
dbt test --target prodyour tables are created first and tested afterward.
If a test fails, your corrupted data is already out there – exposed in dashboards seen by business stakeholders and potentially being used in machine learning models by Data Scientists. Once trust is lost, it’s difficult and demanding to earn it back.
Using `dbt build` doesn't solve this issue; it just combines the commands.
TL;DR:
dbt first creates the tables and then runs the tests on it (except for unit tests)
The Fix
In software engineering, there's a concept called blue-green deployment.
The data world has its own version, introduced by Netflix about 7-8 years ago:
The “Write-Audit-Publish” (WAP)-Pattern, which has become more and more popular in recent years.
The concept is simple but powerful:
Write your tables into a secure space
Audit them for correctness
Publish only if everything checks pass
The beauty of this approach is that in case your tests fail, the publish step won’t be executed. So in the worst case, your stakeholders see slightly outdated data, but they never see data that failed the tests (unlike with the default approach).
The Implementation
There are several ways to implement this pattern in dbt. Let's look at three approaches:
The Simple Approach
The easiest method is to leverage dbt's environment profiles. Along with your existing development and production environments, create a new "audit" environment pointing to a separate schema.
/profiles.yml
my_dbt_project:
target: dev
outputs:
dev:
type: bigquery
method: oauth
project: GCP_PROJECT_ID
dataset: dbt_dev
prod:
type: bigquery
method: oauth
project: GCP_PROJECT_ID
dataset: dbt_prod
audit:
type: bigquery
method: oauth
project: GCP_PROJECT_ID
dataset: dbt_audit
The pipeline execution process would be:
Run `dbt run` in the audit target
Run `dbt test` in the audit target
If tests succeed, run `dbt run` in the production target
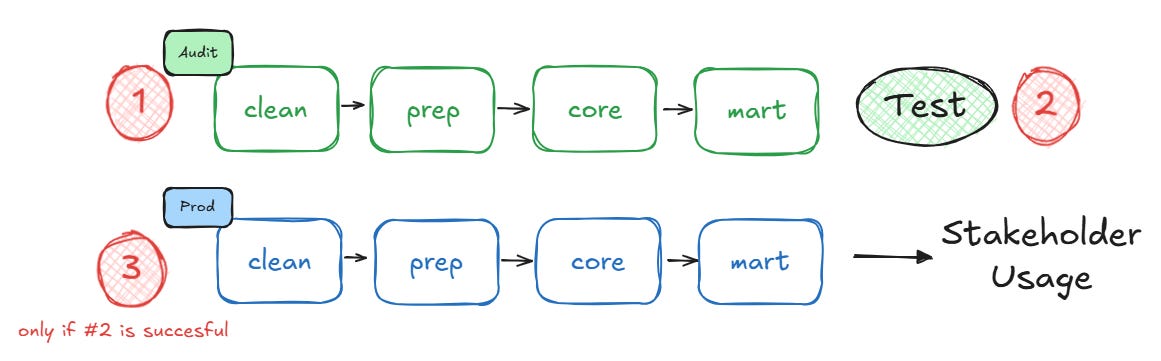
dbt run --target audit
dbt test --target audit
# if prior steps successful:
dbt run --target prodThe upside? This approach can be very simply implemented everywhere.
The downside? You're duplicating compute resources, as you literally run your whole pipeline twice. This can get expensive in large setups, but might be reasonable if you have very little cloud spend or fixed pricing mechanisms.
The “Calogica” Approach
I name it after the Consultancy I’ve seen this using first.
It’s a slightly advanced version of the first approach, making better use of your layered architecture. Here's how it works:
Compute the clean- and prep-layers just once (where most of the heavy lifting happens)
Materialize the core- and mart-layers in the audit-schema
Test everything
If successful, replicate core- and mart-layers to production, referencing the models from Step 1
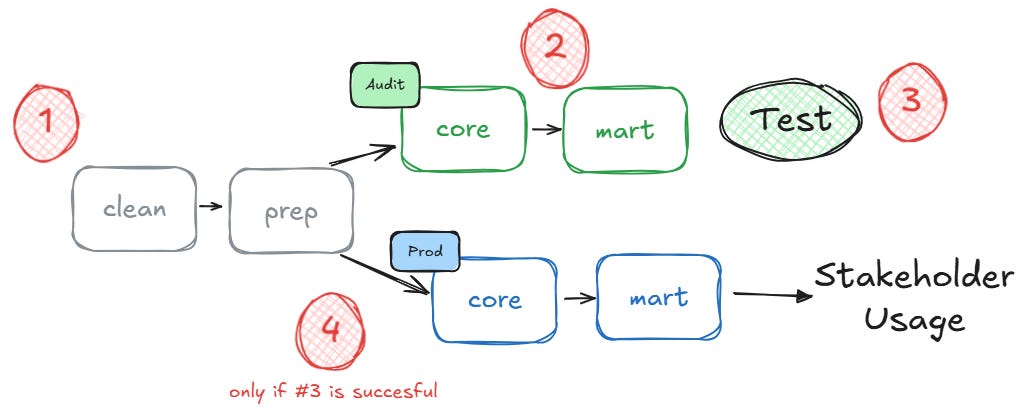
The implementation is also rather quick:
You would put the same schema in your profile.yml’s audit-target as for the prod-target. The magic here would be to tweak the default generate_schema_name-macro to make sure only your core- and mart-models are written to the _audit-schema
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name in ["clean", "prep"] and target.name == 'audit' -%}
{{ default_schema }}_audit
{%- elif custom_schema_name is none -%}
{{ default_schema }}
{%- else -%}
{{ default_schema }}_{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}(Please do not copy/paste the code. It’s not validated, just for illustration)
Since most of your heavy business logic should happen as early as possible (in the prep-layer), this approach significantly reduces the “duplicated compute costs” while maintaining the same data quality safeguards as before.
Both approaches work database agnostic and with dbt core as well as dbt Cloud.
The Swap
For more advanced implementations, you can set up table- or schema-swaps:
It’s the closest to the blue-green-deployment of software engineering since the tables or database-schemas are physically swapped.
In Snowflake you can swap a whole schema
BigQuery requires more tinkering (e.g. through an Orchestrator)
There are good resources available on how to implement it for Snowflake.
The beauty of swapping the tables is that you just need to run the pipelines once.
No extra computing cost is required.
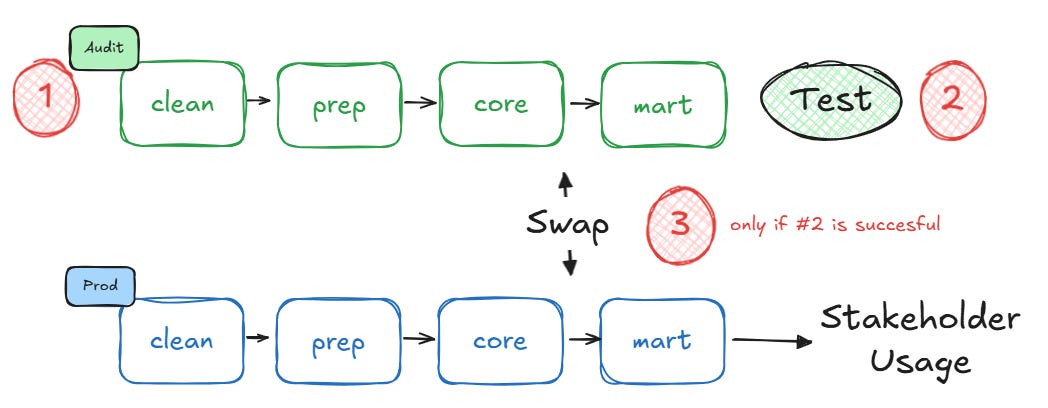
However, this setup makes the most sense for larger organizations or complex data pipelines. The extensive use of post-hooks leads to more complicated dev workflows and implementation efforts, so doing this step through a Workflow Orchestrator (e.g. Airflow or Dagster) might make sense.
Therefore make sure that the resources invested into the swapping mechanism are worth it compared to the other simpler approaches.
The Bottom Line
The Write-Audit-Publish pattern is your safety net for data quality.
Sure, in the worst case, your stakeholders might complain about slightly outdated data (like having Friday's data on Monday morning). But that's far better than making decisions based on incorrect data or losing their trust because they don’t know if they can work with the data.
So please, do yourself and your stakeholders a favor and implement the WAP pattern in your dbt projects. Your future self (and your stakeholders) will thank you.
It’s also important to not clog your pipeline with too many failing tests and proactively alert your stakeholders, but this I’ll address in future posts :)
Appreciate this post. Noticed you didn't mention Databricks - is there tinkering involved there as well or can you do a schema swap just as you can with Snowflake?