
Why Data Modeling is Broken
And how trellis can fix It

When data transformations got simpler and “democratized”, it didn’t just change how we work. It created a whole new cohort of data practitioners.
But here’s the twist: many of these folks (including me) were unfamiliar with established data modeling methods and tooling. The result? Concepts like “building one single ‘master’ customer-table we reference from” felt natural to me, but this is not always the case. In practice, you will encounter a lot of model-sprawl as Query-driven modeling took over, and data modeling was sidelined as uncool, boring, and simply unnecessary.
But now, thanks to AI, Ontologies, and Semantic Layers, Data Modeling is back in the spotlight. Why? Because we are all dreaming of the single version of truth (SVOT) to rely on for analytics — or AI — which is impossible without a solid data model. As Timo Dechau pointed out in his great retrospective about dbt’s impact, tools like dbt nailed a lot: version control, code-first transformations, and data quality tests. But they’re transformation-centric and in my view obsessed with developer experience.
They help you to build things right, but not necessarily to ybuild the right things.
The Problem: Data Modeling is Stuck in the Past
1. Conceptual Modeling is Manual and Forgotten
Most of us still do conceptual modeling in Lucidchart, Draw.io, or Miro.
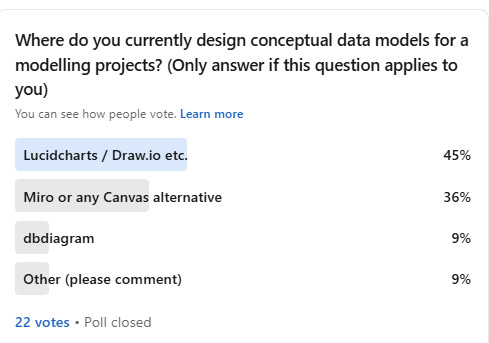
It’s manual, easily forgotten, and often deprioritized because it’s “just documentation”. Packages like dbt-diagrams help keep ERDs up to date, but they’re just “static printouts” of your physical implementation. They don’t help you align on what your data model should be in the first place—the conceptual work of defining metrics, dimensions, and business logic.
2. Legacy Tools Are Clunky and Inflexible
Generally, there’s no shortage of DWH Automation Tools (many from Europe), which partly explains why they’re less familiar to US and international practitioners accustomed to dbt. However, usually they are more end-to-end, UI-focussed and don’t bother to integrate with dbt in some way, because of an inherently different approach: They are metadata-driven. You define entities and attributes upfront, add some custom snippets, and the SQL is auto-generated.
The catch: you lose control over transformations, query performance, and you lock your business logic into a proprietary UI.
If the tool changes or you want to switch, you’re stuck.
3. dbt is Transformation-First, Not Modeling-First
dbt excels at version control, code-first workflows, and testing, but it’s focused on transformations. It doesn’t guide you on what to build. Meanwhile, BI tools and semantic layers (like Lightdash, Omni, and Open Semantic Interchange) are pushing for a structured exchange of semantic definitions. And since dbt is right in the mix, this openness is something I don’t want to miss anymore.
I wanted data modeling to be a first-class citizen in modern data workflows.
I unfortunately did not run into it so far, so I decided to vibe-code it myself:
trellis—A lightweight, code-first approach
How It Works
Lightweight: Just `
pip install`, store version-controlled definitions in YAML files in your dbt repo. No proprietary UI, no vendor lock-in.Zoom In, Zoom Out: Dynamically switch between conceptual and logical views. Filter on only the tables you need to see. Align on definitions, then implement—all in one place.
Tightly coupled with dbt-core*: Trellis reads and writes to your dbt project, so your modeling and physical implementations stay in sync.
Code-First: Model definitions live in YAML, not an UI. Easier to batch-edit or search.
* In my vision, the idea would work on anything that offers an equivalent of dbt’s manifest.json and catalog.json files to serve the required metadata.
The focus is to test the feasibility with the most popular standard first.
Trellis is my attempt to make modeling effortless, code-first and maybe even a bit exciting. Ideally, it would be a native feature, but it isn’t yet. It’s early days—there are bugs, and I’m not a Software Engineer—but I’m sharing it because data modeling deserves better :)
Links:
Try It Out and Share Your Thoughts
If you’re tired of updating Lucid-Diagrams, but see the value in Conceptual Data Modeling, please give trellis a spin. It’s open-source, lightweight, and designed to fit into your dbt workflow.
And if you have feedback (or find a bug), let me know—I’d love to hear from you.
Looking forward to a smoother data modeling experience in 2026!
Happy Holidays!