


Effectively Handling Failures in Data Pipelines
... and strengthen stakeholder trust

Failures in data pipelines are inevitable, but how you handle them can make all the difference. In this post, I'll share some tips on effectively managing these failures and keeping stakeholders informed.
Inform Stakeholders
When something breaks, it's crucial to have stakeholders informed. They should know what to do/use and what not to use. For example, if a data pipeline fails on a Monday morning, stakeholders need to know if they can use the dashboards (or which ones) or if the data is incomplete. For some people and use cases, having recent data up to yesterday is crucial; for some general analysis, it’s not a deal breaker.
You might think that telling stakeholders about a failure is reducing trust, but in my view, it’s strengthening it when you show ownership and accountability.
Kevin Hu from Metaplane coined the term “executive-driven-testing”:
Having stakeholders report problems to you is not ideal, but unfortunately way too often the case.
Automated Notifications
Ideally, automated stakeholder notifications should be set up in communication tools like Slack or Microsoft Teams. These notifications should clearly state what is affected and what is still functional. For instance, if a data pipeline fails, the notification could say:
"The data pipeline failed to update yesterday's data. Dashboards may not reflect the latest information. Please use alternative data sources for now."
Separate Communication Flows
It's beneficial to have two different communication flows:
One for consumers affected by the issue
One for people (e.g. data engineers), who can resolve the issue
The stakeholder notification should clearly indicate what's affected and what's good, while the message to the engineers should include details like the pipeline name, sample records of failed tests, and links to relevant tools like Airflow or Dextra deck.
For dbt test failures, the open-source Elementary package is great to get started quickly and include context about the failures, without too much tinkering.
For example, a message to engineers might look like this:
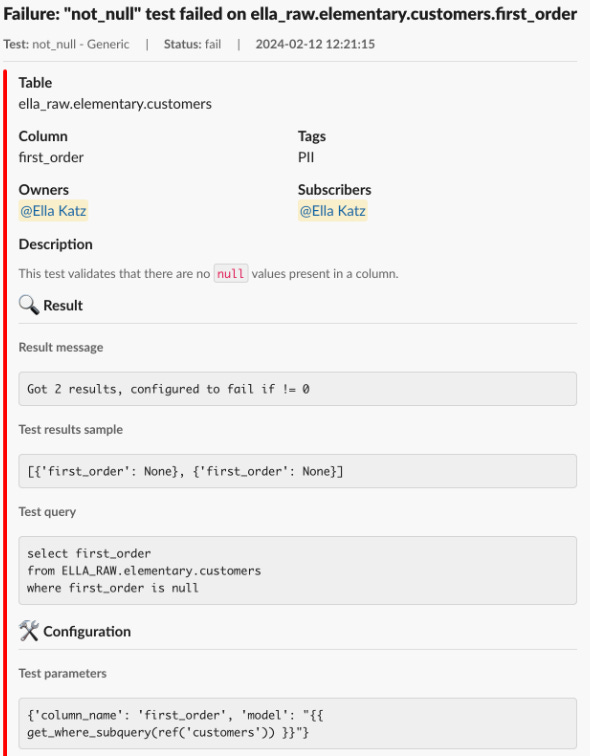
The people resolving the issue can also be non-technical, if the issue is, e.g., a faulty input in the CRM system or outdated Mappings in an Excel file.
Assess the Problem
Not every failure requires extensive fixing. Sometimes, tables fail but are no longer in use. It's essential to figure out if the issue is genuinely a problem to solve.
Monitoring and Deactivation
Use monitoring tools to check if the failed tables are still referenced in your data warehouse. This can be by searching your dbt-project or information-schema.
If they are not used anymore, consider deactivating or even deleting them to avoid confusion and save time.
For example, you can use tools to monitor table usage and set up automated jobs to flag unused tables (this package might help you). If a table hasn't been queried in the last 90 days, it might be a candidate for deactivation.
For most Dashboarding Tools it’s a bit harder, depending on what you use:
Power BI: only self-made or 3rd party solution available
Tableau: For Tableau Server there is a solution. Not sure about Cloud
Looker: Native solution
Looker Studio: connect with Google Analytics4 or use Information Schema
Metabase: paid feature in ther Cloud offering
Lightdash: Also has options built in
Pro Tip: Do not forget about your .csv-dumps and Google Sheet Exports.
Having a documented owner for these saves lots of time and nerves.
A pragmatic, yet lightweight solution for documented ownership is
dbt-exposures. Some BI tools (e.g. Lightdash natively or Metabase through a package) also support creating them automatically.
Refactor and Improve
When fixing a broken pipeline and the issue it not the most urgent, it's an excellent opportunity to refactor and improve the code. Sometimes, the initial logic might have been written with certain anticipations that are no longer relevant.
Refactoring can simplify the process and make it more efficient. Always consider if the current failure can be turned into an opportunity for improvement. For instance, if a pipeline fails due to a complex and outdated transformation logic, you might refactor it to use a more efficient algorithm or leverage new features in your data processing tools.
Manage Alerts Effectively
Alert fatigue is a real issue. It's crucial to manage alerts so that your team doesn't start ignoring them.
Categorize Alerts
Separate alerts into categories like critical failures and minor failures.
For example, you might set up alerts in your monitoring system as follows:
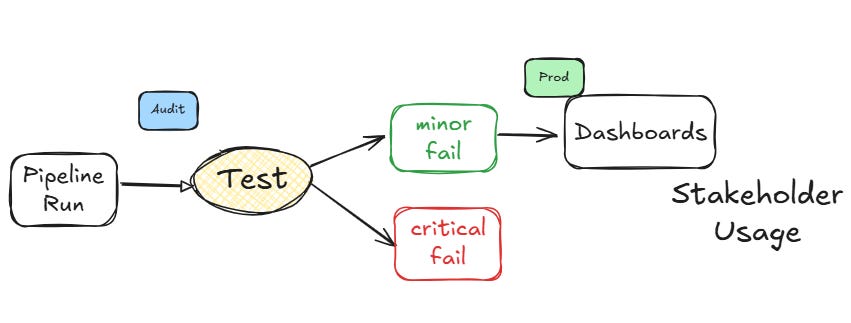
Critical Alerts:
Indicate severe issues that need immediate attention
Examples: Pipeline failure, corrupt revenue calculation
Run with every pipeline execution (to save cost and reduce spam)
Stop the pipeline in a Write-Audit-Publish pattern
Minor Alerts:
Indicate less severe issues that can be addressed during regular maintenance windows,
Examples: minor data inconsistencies or outdated mappings.
Run every day (for hourly pipelines) or every week
Do not stop the pipeline
If you start to ignore alerts, either get rid of them or slow down their intervals.
Conclusion
Handling failures in data pipelines efficiently requires a combination of clear communication and effective monitoring. By keeping stakeholders informed, assessing the real impact of failures, and continuously improving the pipeline, you can ensure a robust and reliable data infrastructure.
Luckily, a lot of things can be automated to save your Monday Mornings :)